General Protocol Concept
The ThingSet protocol provides a consistent, standardized way to configure, monitor and control ressource-constrained devices via different communication interfaces. It specifies the higher layers (5 to 7) of the OSI (Open Systems Interconnection) modelopen in new window. The payload data is independent of the underlying lower layer protocol or interface, which can be CAN, USB, LoRa, WiFi, Bluetooth, UART (serial) or similar.

The underlying layers have to ensure encryption, reliable transfer, correct packet order (if messages are packetized) and error-checking of the transferred data.
Message Types
ThingSet defines three types of messages: Requests, responses and publication messages.
Request/response or client/server model
The communication between two specific devices uses a request/response messaging pattern via so-called channels. A communication channel can be established either directly (e.g. serial interface, USB, Bluetooth) or via a network or bus with several devices attached (e.g. CAN, Ethernet, WiFi, LoRa). In case of a network, each device/node has to be uniquely addressable.
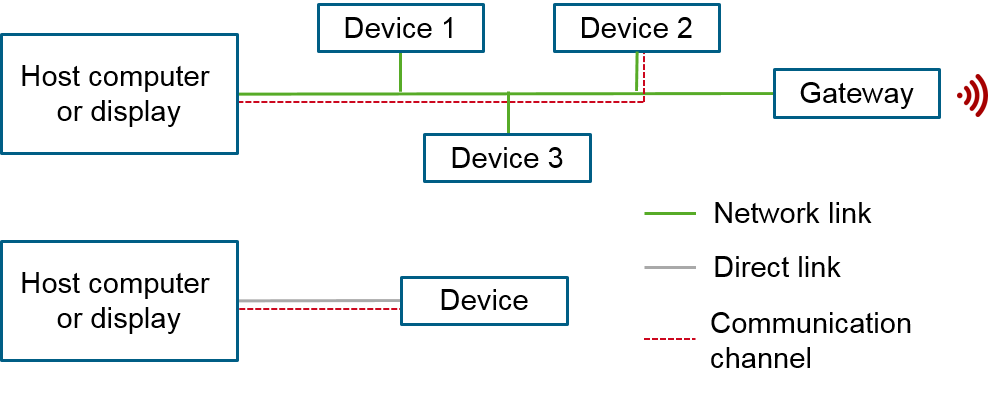
The device acts as the server and responds to the requests by a client. The client might be a laptop or mobile phone with a human interface application.
The data transfer is always synchronous: The client sends a request, waits for the response (status code and/or requested data), handles the data of the response and possibly starts with additional requests.
Publication messages
Monitoring data is not intended for only a single device, but could be interesting for several devices (e.g. data logger, display, human interface device, etc.). Thus, the monitoring data is exchanged via a publish/subscribe messaging pattern.
Publication messages are directly broadcast through the network. There is no intermediate broker (like in MQTT) to store the messages and published messages are not confirmed by recipients, so there is no guarantee if the message was received.
Protocol Modes
Similar to Modbus, the ThingSet protocol supports two different modes: A human-readable text mode and a binary mode.
In the text mode, payload data is encoded in JSON format (RFC 8259open in new window). This mode is recommended when using USB or serial interfaces as the low layer protocol, as it can be easily used directly on a terminal.
The binary protocol uses the CBOR binary encoding (RFC 7049open in new window) instead of JSON payload data in order to reduce the protocol overhead for ressource-constrained devices or low bandwith communication protocols like CAN and LoRa.
Each device must implement the binary encoding of the protocol. The the text-based JSON variant is optional, but recommended.
Data Objects
All accessible data of a device is structured in so-called data objects. A data object might be any kind of measurements (e.g. temperature), device configuration (e.g. setpoint of a controller) or similar.
Each data object is identified by a unique Data Object ID. The ID can be chosen by the firmware developer. In addition to that, each data object has a unique name. The name is a short case-sensitive ASCII string without blanks. If applicable, the unit is appended with an underscore, e.g. "Bat_V" for the battery voltage or "Manufacturer" (without a unit). The underscore is only allowed to separate the name and the unit, there is no additional underscore allowed in the name.
The numeric IDs are used in the binary protocol to reduce message length. For all interactions with users and in the text-based mode, only the object name is used.
Data object categories
Each data object belongs to one of the following categories:
| Category | Description | Access |
|---|---|---|
| info | Device information (e.g. manufacturer, software version) | read access |
| conf | Configurable settings, stored in non-volatile memory after change | read/write access, may be protected with user password |
| input | Input channels (e.g. actuators) | write access |
| output | Output channels (e.g. sensor data) | read access |
| rec | Recorded (history-dependent) data (e.g. error counters) | read access, restricted write access to reset |
| cal | Factory-calibrated settings | read/write access, protected |
| exec | Executable data (remote procedure call) | partly access restricted |
The input and output channels are used for instantaneous data. Changes to an input data object are only stored in RAM, so they get lost after a reset of the device. In contrast to that, conf data is stored in non-volatile memory (e.g. flash or EEPROM) after a change. As non-volatile memory has a limited amount of write cycles, configuration data should not be changed continously.
The recorded data category is used for history-dependent data like error memory, energy counters or min/max values of certain measurements. In contrast to data of output category, recorded data cannot be obtained through measurement after reset, so the current state has to be stored in non-volatile memory on a regular basis.
Factory calibration is only accessible for the manufacturer after authentication.
Excecutable data means that they trigger a function call in the device firmware. Currently, only void functions without any parameters are supported.
Data object IDs are stored as unsigned integers. The firmware developer should assign the lowest IDs to the most used data objects, as they consume less bytes during transfer (see CBOR representation of unsigned integers).
Examples
For explanation of the protocol functions, the following exemplary device data objects will be used:
| Data Object ID | Name | Value | Category |
|---|---|---|---|
| 0x01 | Manufacturer | "Test Company Inc." | info |
| 0x02 | EnableSwitch | true | input |
| 0x03 | Bat_V | 14.2 | output |
| 0x04 | Ambient_degC | 22 | output |
The above data structure contains 4 data objects in total, grouped into 3 different categories (info, input and output). The device will have an internal map to associate the object name, unique ID, category and a pointer to the variable containing the actual data.
Units
All data communicated with the outside world use SI unitsopen in new window and the different numeric data types should be used for scaling instead of prefixes like milli or kilo to the units.
If the basic SI unit for a given measurement value is not common or not feasible (e.g. use of kWh for energy instead of Ws), the unit must be properly defined with an underscore in the name of the data object, e.g. "Battery_kWh" for the battery energy content in kWh. Units which cannot be derived from the SI basic units (e.g. °F) are not recommended.
Functions
Each request fulfills a specified function, e.g. a command to read data from the device. The function is associated to a function ID, which defines the layout of the payload and the actions to be performed.
The different functions are encoded in the first byte of a message, i.e. by a number between 0 and 255.
Function IDs 10, 13 and 32-127 are reserved, as they represent the ASCII characters for readable text including CR and LF. Invalid function IDs are ignored by the ThingSet parser, so that other text output (e.g. status information) can be used in parallel to the ThingSet protocol on the same serial interface.
The ASCII characters '!', '#' and ':' (function IDs 33, 35 and 58) are used as identifiers for the text mode protocol. In this way, text-based or binary mode can be automatically detected based on the first byte.
Function IDs greater than or equal to 128 (0x80) are used for response messages and include a status code which shows if the request could be handled successfully. The function ID is calculated as 0x80 + status code. For status codes between 0 and 31, the response was successful. If the status code is greater than or equal to 32, an error occured.
Details regarding the ThingSet Protocol functions will be explained in the next chapter.